The Fundamentals of Machine Learning
The last few years have brought us incredible advancements in machine learning. These diverse systems are built from a few core building blocks, which are modified and combined in complex ways.
These core ideas often get abstracted away when discussing the bigger picture, leaving us to wonder — “What’s going on inside?”
In this interactive lesson, we will answer that question by thinking small.
We will start with the simplest of models — The Line, and see how it can help us build a Neural Network capable of learning anything. Then, going back to the line, we will learn how to train it using the Gradient Descent algorithm, which we will write from scratch in Python.
Modeling Our World
The power of machine learning lies in its ability to distill down large volumes of data into useful representations we call models.
Think of models like play dough. They have adjustable parameters which let us mold them into various shapes. Training is the process of molding them based on data.
Models generally take in some input(s) and give back an output .
Weights and Biases
The line is one of the simplest of models with just two parameters. The weight controls the line’s tilt and the bias shifts it.
We can generalize this to multiple inputs :
Notice that each input gets scaled by its own weight .
By adjusting these weights, we can tune how much each input influences the value of .
The bias is independent of any input, it simply shifts towards the positive or negative direction.
We can see this in action by plotting a linear model with two inputs, .
Activation Functions
The linear model is… well, linear. But not everything in our world is described in straight lines.
Here’s a non-linear function known as the sigmoid .
It smoothly transitions from to .
Something interesting happens when we pass a linear model into the sigmoid: .
We are able to use the and parameters of the line to change the sharpness and center of the sigmoid’s transition!
This has transformed our line into something like an on-off switch, where we can control the threshold with and represent uncertainty with .
Functions like the sigmoid into which we pass our linear model are known as Activation Functions. There are many of them out there, of which the sigmoid is the most classic example.
Like before, we can extend this to multiple inputs:
Here’s :
If we view it from the top, we see that the activated and non-activated regions are split by a linear boundary.
The model we’ve just created takes in the values of its inputs, scales them by their weights, sums these results with the bias and then feeds the sum into the sigmoid, which then decides whether to activate or not.

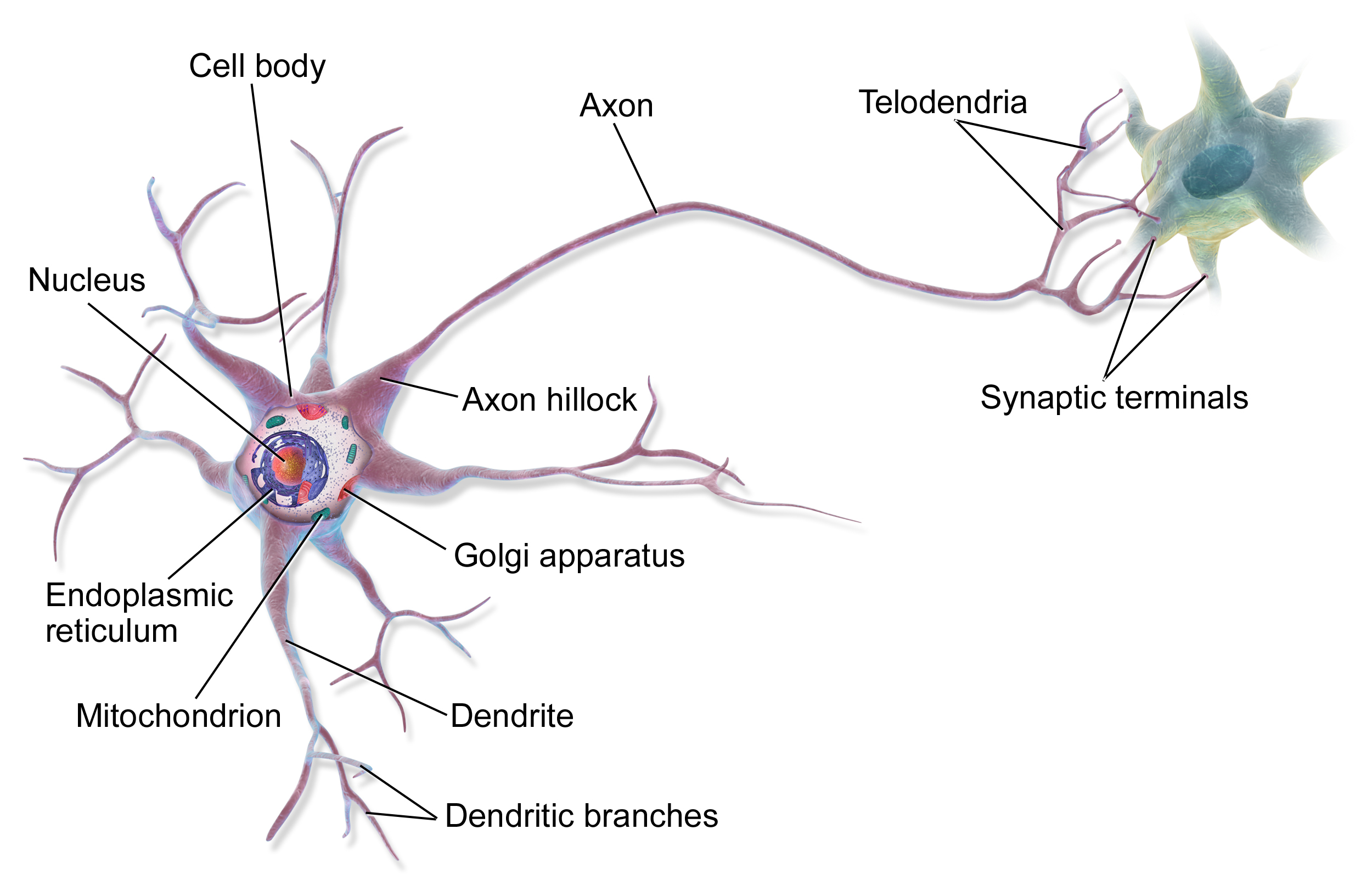
In structure, this is similar to a biological neuron. Dendrites on the neuron’s body receive inputs from other neurons. Based on this, the neuron decides whether it should fire a signal through its axon, to which more neurons may be connected. These connections can grow stronger, analogous to the weights in artificial neurons.
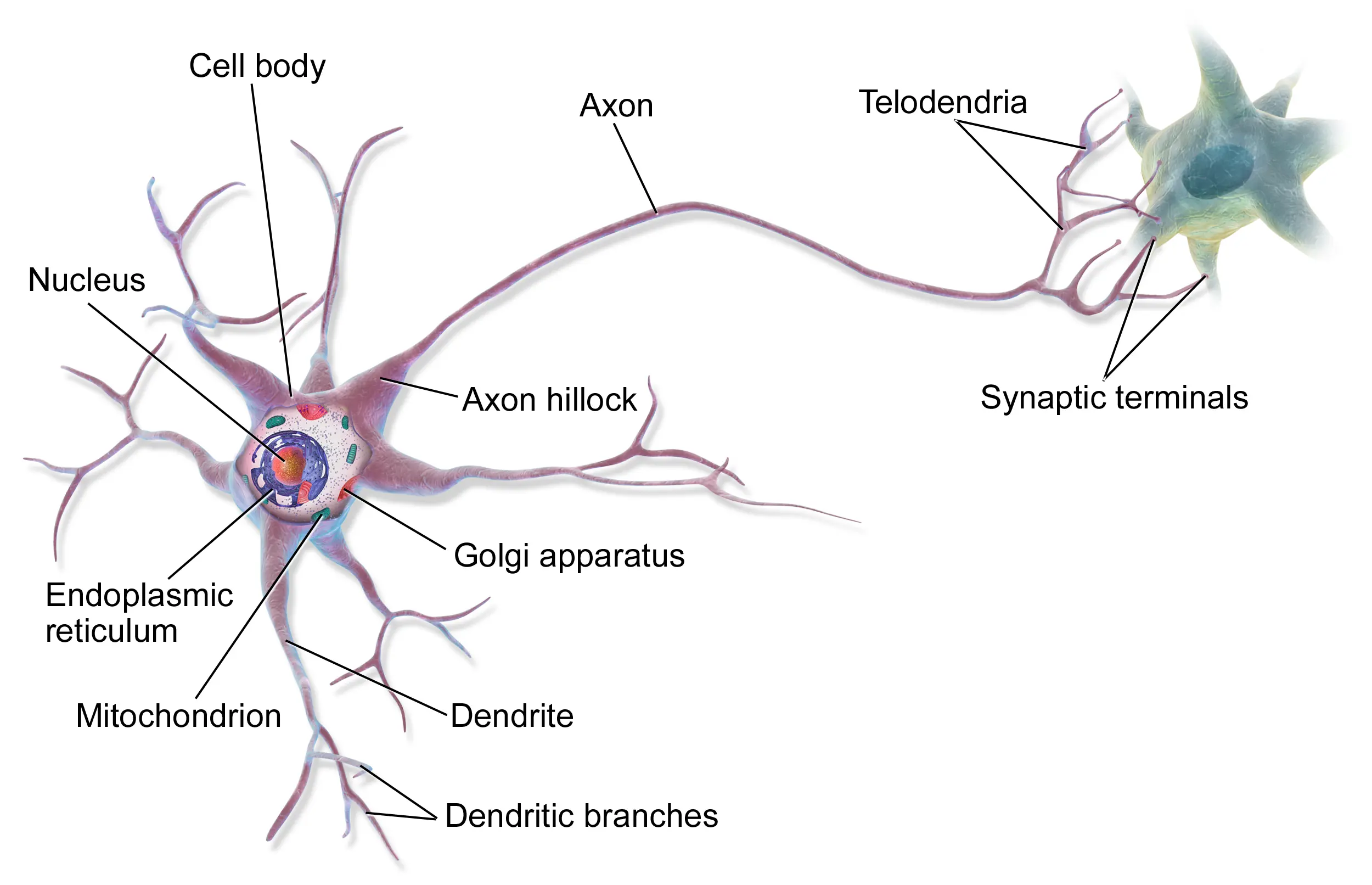 Image credit: Wikipedia.
Image credit: Wikipedia.
{kind=link}
Neural Networks
Like biological neurons, we can treat the outputs of artificial neurons as inputs for other neurons.
Here’s a setup where is a special output neuron (we give it no activation function). Its input is the output of the previous neuron in the chain, this connection adds another adjustable weight.
You can change a value in the diagram by clicking on it and then adjusting the slider.
Tweaking this output weight allows us to scale the range of the sigmoid function, so it’s no longer confined between and !
But we can go further, and add neurons in parallel. Here’s two of them.
They stack on top of each other. Let’s add some more neurons!
This network can be molded to a variety of shapes!
In fact, the more neurons we add, the greater the variety of functions our network can draw. Theoretically, if we had an infinite number of neurons, we could draw any function we like!
But even with a finite number of neurons, we can get very close to our target function.
This is what makes neural networks so powerful. This simple arrangement can be arbitrarily scaled to approximate any function to the degree of accuracy we need. They are Universal Function Approximators.
And because we can describe any input / output relationship in our world as a function, our model can thus also learn anything!
We will now go back to where this all began, to the humble line. The rest of this article explores how models are trained using the Gradient Descent algorithm. Although we will be using the line for our training, the ideas are modular, and they can be applied to individual neurons and also to full blown neural networks.
Creating a model in code
The code block below plots . I’d like you to update this function to plot by using the w and b variables already defined. Once done, click on “Run”. You should be able to use the sliders to control the weight and bias of the line.
Loading editor...
b = 0 w = 1 def y(x, w, b): return x # update this line to use w and b
Great! We now have a model which can fit to some data.
Fitting a model to data
Our data will exist as pairs. Where is the value of some input variable, and is the corresponding output of that variable.
This data could represent anything!
- Maybe you want to predict how many ice-creams you can sell based on the current temperature .
- Or how much energy your solar panels can generate based on the hours of daylight .
- Or if you’re Sherlock, how tall a person is based on the length of their footprint !
In all these cases, we can reasonably assume that and are roughly linearly related. Knowing this, we can choose to use our linear model to fit to this data.
It’s important to keep in mind that data from the natural world is messy. It may have random noise, or may only follow the expected (linear) relationship for a certain range of inputs. We need to be aware of such factors to use our models responsibly.
To keep things simple, we will use some synthetic data for our program.
Now, can you use the sliders to find the values of and that best fit this data?
Loading editor...
data = [(1, 0.85), (2, 1.43), (3, 1.92), (4, 2.59), (5, 3.20), (6, 3.82), (7, 4.38), (8, 4.97)] w = 1 b = 0 def y(x, w, b): return w * x + b
You have just “trained” the model by hand! The values of and you arrived at are the trained parameters of the model. We can use these to get approximations of our data pairs:
Loading editor...
x_values = [1, 2, 3, 4, 5, 6, 7, 8] data = [] # feel free to replace these with the values you found! w = 0.6 b = 0.2 def y(x, w, b): return w * x + b for xi in x_values: # here, we're predicting yi using our model data_point = (xi, y(xi, w, b)) data.append(data_point)
But now we can do more, and also predict for values of that were not in our data!
Loading editor...
x_values = [-3, 6.28] # our model never saw these weird inputs before! data = [] w = 0.6 b = 0.2 def y(x, w, b): return w * x + b for xi in x_values: data_point = (xi, y(xi, w, b)) data.append(data_point)
This is how a trained model is useful. Not only are we storing a more compact representation of the data through its parameters, but we can also get predictions for inputs it never saw before.
This is also true for neurons and neural networks. Which may have more inputs, and more parameters to model a variety of shapes.
Our next goal will be to figure out how to train the model automatically.
The Loss Function
When you fit the line to the data points in the previous section, you were able to visually see how well they were aligned.
But machines don’t see, they crunch numbers. So we need a way to quantify how well the model matches its data.
For any single data point , we can measure the absolute difference between the output and the model’s prediction based on the current values of and , .
Then we can sum these up for every data point.
We have just created a Loss Function, this one is known as loss.
As an alternative to the function, we can also the difference. This gives us the Loss Function named loss and it has a couple of advantages:
- Unlike the modulus function, the square function is differentiable at all points, and we will need that for the Gradient Descent algorithm.
- Since the error gets squared, data points that are way off get penalized a lot more than those which are closer to the line.
The factor here will just make things convenient when computing derivatives!
Let’s see our loss function in action.
Loading editor...
data = [(1, 0.85), (2, 1.43), (3, 1.92), (4, 2.59), (5, 3.20), (6, 3.82), (7, 4.38), (8, 4.97)]
w = 1
b = 0
def loss():
# summation is like a for loop
sum = 0
for xi, yi in data:
# here's the expression inside the summation operation
sum += (y(xi, w, b) - yi) ** 2
# the division is for the 1/2 factor
return sum / 2
def y(x, w, b):
return w * x + b
The Loss Landscape
The Loss Function’s inputs are our model’s parameters — and . We can create a plane, with a -axis and a -axis. Picking any point on this plane would give us a combination of which can be used to represent a unique line.
This plane is our model’s parameter space. We can compute our Loss Function for every point on it, and plot the output on a third axis.
This visualization is known as the Loss Landscape of our model.
Loading editor...
data = [(1, 0.85), (2, 1.43), (3, 1.92), (4, 2.59), (5, 3.20), (6, 3.82), (7, 4.38), (8, 4.97)]
w = 1
b = 0
def loss(w, b):
sum = 0
for xi, yi in data:
sum += (y(xi, w, b) - yi) ** 2
return sum / 2
def y(x, w, b):
return w * x + b
After plotting the Loss Landscape, we can easily see that there’s a point where the loss is the lowest.
To train our model automatically, we want to have it find this point (the values for and ) without computing the entire Loss Landscape.
This seems like a difficult problem, so let’s first look at a simpler, one dimensional case.
Derivatives
The next few sections assume knowledge of Derivatives. We’ll quickly see how they’re useful to us.
Here’s a roller-coaster of a polynomial . If we draw a line tangent to it at some value of , we see that this tangent has a changing slope.
slope of tangent: 1.3000
Since this slope depends on , we can create a function that takes in and returns the slope of the tangent. That function is known as the derivative of .
Derivatives are usually written in the forms or , where is the original function and is the variable we are sliding.
How is this useful? Well, let’s use the widgets above to play a simple game:
- Pick a random value of to start with.
- If the slope is positive, move the slider slightly to the left.
- If instead it is negative, move it to the right.
- Repeat the last two steps, and you will always end up in a “valley” of the graph.
This works because the derivative always tells us which direction the function is increasing in. By going in the opposite direction (going left when the slope is positive), we always head downhill.
That’s exactly what we’re looking to do with our Loss Function too! But we still have one problem: our Loss Function has two inputs, not one.
So we will need to do something clever about that.
Partial Derivatives
If we fix one of the inputs to some constant, say , then we’ve converted our two-variable Loss Function into a single variable function, because we can only adjust the other variable ().
This would allow us to compute the derivative of this function like any other single variable function.
Partial Derivatives are based on this idea. Except, the other variables are only treated as constants, and are not actually set to any numeric value.
We will instead set them to specific constants when we are evaluating the slope!
Our Loss Function has two variables, and thus, two partial derivatives, and .
Let’s say we are at a point . Then evaluating here will fix (the variable we are not differentiating) to , giving us a single variable function of . The slope along the axis is returned for .
Similarly, will give us the slope along the axis at the same point .
Gradients
When we combine both of these partial derivatives into a single vector, we call that vector the Gradient Vector .
The Gradient is to our Loss Landscape what the slope was to the polynomial. Imagine standing on the side of a hill. The Gradient tells you which direction is downwards, and how steep the ground beneath your feet is.
The Gradient of our Loss Function
Here’s our Loss Function again:
We will need to find the partial derivatives for both and . Let’s start with first.
The summation operator can make things messy. Since the derivative of a sum is equal to a sum of the derivatives, let’s put this operator outside the partial differentiation step.
Now, we could go ahead and differentiate this directly, but there is an easier way out, that will also scale well for more complex models.
A worthy observation is that we are differentiating a composite function, i.e. a function within a function.
I’ve written the outer function in and the inner one in .
When we need to find derivatives of composite functions, we can use a property known as the Chain Rule to do this in a clean way.
The Chain Rule
Here’s the property. Let’s say we have two functions and , and we use them to create a composite function :
The Chain Rule says that we can get the derivative in the form of this product:
Here, is simply the regular derivative of . But what is ?
Let’s say was equal to , then would be .
But with , the input to is now instead of just . So the derivative of with respect to this new input is written as and is computed to be . We just replaced the in with a .
This is helpful, because it’s easy to know the derivative of or individually. But to compute these derivatives for would be much more involved. The chain rule helps us take a shortcut by using the atomic derivatives instead.
Let’s apply the Chain Rule on our Loss Function.
Note that we are naming to be the outer function . We can ignore here, because it is a constant which gets dropped during differentiation.
So we have to find and . Let’s start with the latter.
Recall the equation of the line :
When we’re computing the partial derivative with respect to , it remains a variable and everything else ( in this case) is treated to be a constant. Therefore, we get:
Now let’s work with the other part, . Our outer function is . It’s derivative is , which simplifies to just , the input. In our case our input is .
We’ve computed both parts from the chain rule, let’s multiply them together:
And we have the partial derivative for ! Now we do the same for .
We previously computed the first part to be . Let’s look at the second:
Now we multiply the two together:
We now have the partial derivatives for our two parameters! Let’s package them into the Gradient Vector.
Let’s try to visualize the Gradient vector on the Loss Landscape. Remember that we had moved the summation operators aside, we will need to add that back.
Loading editor...
data = [(1, 0.85), (2, 1.43), (3, 1.92), (4, 2.59), (5, 3.20), (6, 3.82), (7, 4.38), (8, 4.97)]
w = 1
b = 0
def loss(w, b):
sum = 0
for xi, yi in data:
sum += (y(xi, w, b) - yi) ** 2
return sum / 2
def gradient():
# we'll keep track of the two sums in dw and db
dw = db = 0
for xi, yi in data:
# the two expressions in our gradient vector
dw += (y(xi, w, b) - yi) * xi
db += y(xi, w, b) - yi
return dw, db
def y(x, w, b):
return w * x + b
loss(w,b) = 0
We see that the Gradient Vector is incredibly large. This is because of the steepness of the Loss Landscape. You can try to reach to the shallower regions and see the vector change size and direction.
Due to its size, it may appear that the vector is pointing the wrong way, but it does not know where the valley is. It only tells us which direction is downward at the point it was evaluated on.
Steps in the Right Direction
We will now try to use the information in the Gradient Vector to update our model’s parameters!
Since as we just saw, the size of this vector is gigantic, we will scale it down by a factor. This is normally known as the learning rate or the step size.
Then we will update the parameters and to where the scaled gradient vector tells them to go.
The choice of the learning rate is critical here. Too low, and the steps will be too small to reach our goal in a reasonable time. Too high, and our steps may overshoot our goal.
In the next code block, I’ve added a learning_rate variable. But I think I set it too high!
Can you try to find a good learning rate for our data?
Loading editor...
data = [(1, 0.85), (2, 1.43), (3, 1.92), (4, 2.59), (5, 3.20), (6, 3.82), (7, 4.38), (8, 4.97)]
w = 1
b = 0
def loss(w, b):
sum = 0
for xi, yi in data:
sum += (y(xi, w, b) - yi) ** 2
return sum / 2
def gradient():
dw = db = 0
for xi, yi in data:
dw += (y(xi, w, b) - yi) * xi
db += y(xi, w, b) - yi
return dw, db
def y(x, w, b):
return w * x + b
# can you find a better value for this?
learning_rate = 0.01
def update():
dw, db = gradient()
global w,b
w -= dw * learning_rate
b -= db * learning_rate
b = 0
gradient() = 0
loss(w,b) = 0
You know you’ve found a good learning rate when the model starts to find stability in its movement after quickly getting closer to matching the data.
Great! We are able to get our model to fit closer to the data, a step at a time!
The Gradient Descent Algorithm
Now we just need to run these steps in a loop!
The new train() function will be called by the controls below. Normally, models are trained for a fixed number of iterations, but in this case the parameter iterations is instead being used to control the speed of the animation.
I’d like you to call the update() function inside the for loop to finish this off! :)
Loading editor...
data = [(1, 0.85), (2, 1.43), (3, 1.92), (4, 2.59), (5, 3.20), (6, 3.82), (7, 4.38), (8, 4.97)]
w = 1
b = 0
learning_rate = 0.001
def y(x, w, b):
return w * x + b
def gradient():
dw = db = 0
for xi, yi in data:
dw += (y(xi, w, b) - yi) * xi
db += y(xi, w, b) - yi
return dw, db
def update():
dw, db = gradient()
global w,b
w -= dw * learning_rate
b -= db * learning_rate
return w, b
iteration_counter = 0
def train(iterations = 100):
global iteration_counter
for i in range(iterations):
# call update() in this loop!
iteration_counter += 1
w = 0
b = 0
It’s just the beginning…
We’ve finally seen how machine learning models can be trained, and we’ve learnt this in detail by focusing on a simple model.
There are many paths from here. We can extend our code to multiple variables, or add an activation function, or even do both to create neural networks. We can also try different kinds optimization techniques.
Perhaps, you want to train a model for some data that interests you!
Whatever that may be, I hope that you keep learning more about this fascinating subject!
Thank you for reading!
This lesson is an entry for the Summer of Math Exposition 4. Every year, it brings together a variety of math content to love! Go check them out!
While you’re at it, I want to mention Jumplion’s entry where he uses math to find The Best Phonetic Alphabet. I helped him out in a step of the audio analysis part.